
咨询电话
400-123-4567
手 机:13988999988
电 话:400-123-4567
传 真:+86-123-4567
邮 箱:admin@baidu.com
地 址:广东省广州市天河区88号
电 话:400-123-4567
传 真:+86-123-4567
邮 箱:admin@baidu.com
地 址:广东省广州市天河区88号

微信扫一扫
阿里巴巴·汤蒂·凯伊恩(Alibaba Tongyi Kaiyuan)的想
作者:365bet体育注册日期:2025/07/07 19:11浏览:
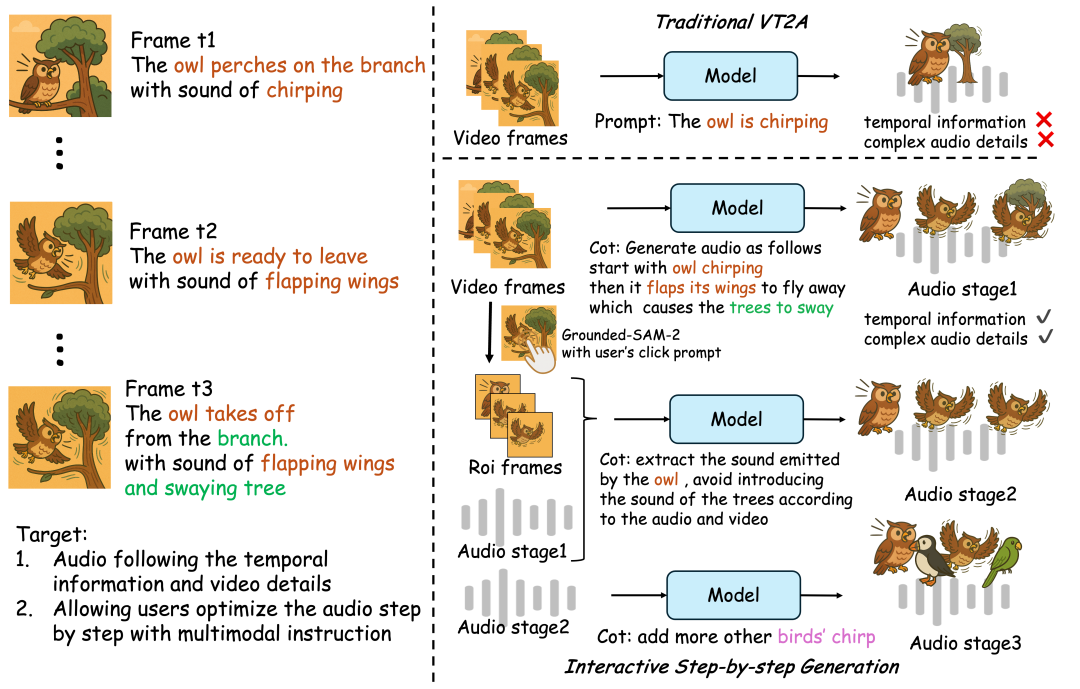 7月4日的Home报道说,阿里巴巴的“ Talyyi Big Model”现在宣布,在第一次汤蒂实验室一代之后,它是正式开放的资源,这将破坏“安静图像”的想象力。 Thinksound applied the cot (chain-of-thinking) to the field of audio generation for the first time, allowing AI to learn to "think clearly" the relationship between photo and sound events, thus achieving high honesty and strong coincides spatial audio generation-not just "looking" and dubbing ". To learn AI to "listen logically", the Tongyi Laboratory Voice Team built the first multimodal audio dataset, audiocot, which supports chain推理。来自多个Tulle Resources Vggsound Ads,Audiosets,Audiocaps,Freestounds等的2531.8小时的高质量样本,以确保每个数据都可以真正支持AI的结构化的辩论能力Matic过滤质量和手动采样验证至少为5%,以逐层检查此层,以确保整体质量的数据集。在此基础上,Audiocot还专门设计了交互式编辑的教学水平和教学级别,以满足随后阶段的精炼和编辑功能的思维需求。思考包括两种主要成分:一种多模式的大语言模型(MLLM),它在“思考”方面非常出色,以及一个专门用于“审核输出”的音频生成模型。这是两个模块的合作,该模块提供了在三个阶段逐渐研究屏幕内容的系统,并最终从了解一般图片(关注特定对象),然后对用户指令做出响应。根据官方报道,尽管近年来端到端视频到原告(V2A)的一代技术有重大发展,但仍然很难真正地真正地获取动态细节和空间照片关系。诸如猫头鹰在抽搐,起飞时,诸如摩擦声音颤抖时的视觉声音关联通常会被忽略,从而导致发达的音频过于笼统,甚至是对基本视觉事件的误解,那么使它很难与专业创意的场景有关。其背后的主要问题是,AI缺乏对照片事件的结构化理解,无法评估,理性和综合人类声音效应器之类的声音步骤。它配备了一个开放地址资源:https://github.com/funaudiollm/thinksoundhttps://huggingface.co/spaces/funaudiollm/thinksoundhttps://wwwww.models.cn/models.cn/studioscope.cn/studios/thstudios/think/thinkinksound/iic/thinkinksoundsound/thinksoundound
7月4日的Home报道说,阿里巴巴的“ Talyyi Big Model”现在宣布,在第一次汤蒂实验室一代之后,它是正式开放的资源,这将破坏“安静图像”的想象力。 Thinksound applied the cot (chain-of-thinking) to the field of audio generation for the first time, allowing AI to learn to "think clearly" the relationship between photo and sound events, thus achieving high honesty and strong coincides spatial audio generation-not just "looking" and dubbing ". To learn AI to "listen logically", the Tongyi Laboratory Voice Team built the first multimodal audio dataset, audiocot, which supports chain推理。来自多个Tulle Resources Vggsound Ads,Audiosets,Audiocaps,Freestounds等的2531.8小时的高质量样本,以确保每个数据都可以真正支持AI的结构化的辩论能力Matic过滤质量和手动采样验证至少为5%,以逐层检查此层,以确保整体质量的数据集。在此基础上,Audiocot还专门设计了交互式编辑的教学水平和教学级别,以满足随后阶段的精炼和编辑功能的思维需求。思考包括两种主要成分:一种多模式的大语言模型(MLLM),它在“思考”方面非常出色,以及一个专门用于“审核输出”的音频生成模型。这是两个模块的合作,该模块提供了在三个阶段逐渐研究屏幕内容的系统,并最终从了解一般图片(关注特定对象),然后对用户指令做出响应。根据官方报道,尽管近年来端到端视频到原告(V2A)的一代技术有重大发展,但仍然很难真正地真正地获取动态细节和空间照片关系。诸如猫头鹰在抽搐,起飞时,诸如摩擦声音颤抖时的视觉声音关联通常会被忽略,从而导致发达的音频过于笼统,甚至是对基本视觉事件的误解,那么使它很难与专业创意的场景有关。其背后的主要问题是,AI缺乏对照片事件的结构化理解,无法评估,理性和综合人类声音效应器之类的声音步骤。它配备了一个开放地址资源:https://github.com/funaudiollm/thinksoundhttps://huggingface.co/spaces/funaudiollm/thinksoundhttps://wwwww.models.cn/models.cn/studioscope.cn/studios/thstudios/think/thinkinksound/iic/thinkinksoundsound/thinksoundound相关文章
- 2025/10/05有多少塔卡西·塞米(Takashi Saemi)想打架
- 2025/10/05王·楚平(Wang Chuqin)和林·希(Lin Shido
- 2025/10/04在1962年中印度 - 印度边界战争的前夕,毛
- 2025/10/04凯夫伦